1 Introduction
CWL (Common Workflow Language) is an open standard for describing analysis workflows and tools in a way that makes them portable and scalable across a variety of software and hardware environments.
ccwl (Concise Common Workflow Language) is a concise syntax to express CWL workflows. It is implemented as an EDSL (Embedded Domain Specific Language) in the Scheme programming language, a minimalist dialect of the Lisp family of programming languages.
ccwl is a compiler to generate CWL workflows from concise descriptions in ccwl. In the future, ccwl will also have a runtime whereby users can interactively execute workflows while developing them.
2 Tutorial
This tutorial will introduce you to writing workflows in ccwl. Some knowledge of CWL is assumed. To learn about CWL, please see the Common Workflow Language User Guide
2.1 Important concepts
The CWL and ccwl workflow languages are statically typed programming languages where functions accept multiple named inputs and return multiple named outputs. Let’s break down what that means.
2.1.1 Static typing
In CWL, the type of arguments accepted by a function and the type of outputs returned by that function are specified explicitly by the programmer, and are known at compile time even before the code has been run. Hence, we say that it is statically typed.
2.1.2 Positional arguments and named arguments
In many languages, the order of arguments passed to a
function is significant. The position of each argument determines
which formal argument it gets mapped to. For example, passing
positional arguments in Scheme looks like (foo 1
2). However, in a language that supports named arguments (say,
Scheme or Python), the order of arguments is not significant. Each
argument explicitly names the formal argument it gets mapped to. For
example, in Scheme, passing named arguments may look like (foo
#:bar 1 #:baz 2) and is equivalent to (foo #:baz 2 #:bar
1). Likewise, in Python, passing named arguments looks like
foo(bar=1, baz=2) and is equivalent to foo(baz=2,
bar=1).
2.1.3 Multiple function arguments and return values
In most languages, functions accept multiple input arguments but only return a single output value. However, in CWL, a function can return multiple output values as well. These multiple outputs are unordered and are each addressed by a unique name.
2.2 First example
As is tradition, let us start with a simple Hello World workflow in ccwl. This workflow accepts a string input and prints that string.
(define print (command #:inputs (message #:type string) #:run "echo" message)) (workflow ((message #:type string)) (print #:message message))
The first form in this code defines the print
command. This form is the equivalent of defining a
CommandLineTool class workflow in CWL. The arguments after
#:inputs define the inputs to the workflow. The arguments
after #:run specify the command that will be run. The input
(message #:type 'string) defines a string type
input named message. The command defined in the
#:run argument is the command itself followed by a list of
command arguments. One of the arguments references the input
message. Notice how the command definition is very close to
a shell command, only that it is slightly annotated with inputs and
their types.
The second form describes the actual workflow and is the
equivalent of defining a Workflow class workflow in CWL. The
form ((message #:type string)) specifies the inputs of the
workflow. In this case, there is only one input---message of
type string. The body of the workflow specifies the commands
that will be executed. The body of this workflow executes only a
single command---the print command---passing the
message input of the workflow as the message input
to the print command.
If this workflow is written to a file hello-world.scm, we may compile it to CWL by running
$ ccwl compile hello-world.scm
This prints a big chunk of generated CWL to standard output. We have achieved quite a lot of concision already! We write the generated CWL to a file and execute it using (command "cwltool") as follows. The expected output is also shown.
$ ccwl compile hello-world.scm > hello-world.cwl $ cwltool hello-world.cwl --message "Hello World!" [workflow ] start [workflow ] starting step print [step print] start [job print] /tmp/guix-build-ccwl-website.drv-0/2vi9umyu$ echo \ '"Hello World!"' "Hello World!" [job print] completed success [step print] completed success [workflow ] completed success {}Final process status is success
2.3 Capturing the standard output stream of a command
Let us return to the Hello World example in the
previous section. But now, let us capture the standard output of the
print command in an output object. The ccwl code is the same
as earlier with the addition of an stdout type output object
and an #:stdout parameter specifying the name of the file to
capture standard output in.
(define print (command #:inputs (message #:type string) #:run "echo" message #:outputs (printed-message #:type stdout) #:stdout "printed-message-output.txt")) (workflow ((message #:type string)) (print #:message message))
Let’s write this code to a file
capture-stdout.scm, generate CWL, write the generated CWL to
capture-stdout.cwl, and run it using cwltool. We
might expect something like the output below. Notice how the standard
output of the print command has been captured in the file
printed-message-output.txt.
$ ccwl compile capture-stdout.scm > capture-stdout.cwl $ cwltool capture-stdout.cwl --message "Hello World!" [workflow ] start [workflow ] starting step print [step print] start [job print] /tmp/guix-build-ccwl-website.drv-0/dgx913xp$ echo \ '"Hello World!"' > /tmp/guix-build-ccwl-website.drv-0/dgx913xp/printed-message-output.txt [job print] completed success [step print] completed success [workflow ] completed success { "printed-message": { "location": "file:///home/manimekalai/printed-message-output.txt", "basename": "printed-message-output.txt", "class": "File", "checksum": "sha1$b55dbc4ecb0cec94a207406bc5cde2f68b367f58", "size": 15, "path": "/home/manimekalai/printed-message-output.txt" } }Final process status is success
2.4 Capturing output files
In the previous section, we captured the standard output stream of a command. But, how do we capture any output files created by a command? Let us see.
Consider a tar archive hello.tar containing a file hello.txt.
$ tar --list --file hello.tar hello.txt
Let us write a workflow to extract the file
hello.txt from the archive. Everything in the following
workflow except the #:binding parameter will already be
familiar to you. The #:binding parameter sets the
outputBinding field in the generated CWL. In the example
below, we set the glob field to look for a file named
hello.txt.
(define extract (command #:inputs (archive #:type File) #:run "tar" "--extract" "--file" archive #:outputs (extracted-file #:type File #:binding ((glob . "hello.txt"))))) (workflow ((archive #:type File)) (extract #:archive archive))
Writing this workflow to capture-output-file.scm, compiling and running it gives us the following output. Notice that the file hello.txt has been captured and is now present in our current working directory.
$ ccwl compile capture-output-file.scm > capture-output-file.cwl $ cwltool capture-output-file.cwl --archive hello.tar [workflow ] start [workflow ] starting step extract [step extract] start [job extract] /tmp/guix-build-ccwl-website.drv-0/kpzck6qf$ tar \ --extract \ --file \ /tmp/guix-build-ccwl-website.drv-0/v1b16wuy/stge3e22ede-56ec-453d-a9a3-151623b02563/hello.tar [job extract] completed success [step extract] completed success [workflow ] completed success { "extracted-file": { "location": "file:///home/manimekalai/hello.txt", "basename": "hello.txt", "class": "File", "checksum": "sha1$a0b65939670bc2c010f4d5d6a0b3e4e4590fb92b", "size": 13, "path": "/home/manimekalai/hello.txt" } }Final process status is success
The above workflow is not awfully flexible. The name of the
file to extract is hardcoded into the workflow. Let us modify the
workflow to accept the name of the file to extract. We introduce
extractfile, a string type input that is passed to
tar and is referenced in the glob field.
(define extract-specific-file (command #:inputs (archive #:type File) (extractfile #:type string) #:run "tar" "--extract" "--file" archive extractfile #:outputs (extracted-file #:type File #:binding ((glob . "$(inputs.extractfile)"))))) (workflow ((archive #:type File) (extractfile #:type string)) (extract-specific-file #:archive archive #:extractfile extractfile))
Compiling and running this workflow gives us the following output.
$ ccwl compile capture-output-file-with-parameter-reference.scm > capture-output-file-with-parameter-reference.cwl $ cwltool capture-output-file-with-parameter-reference.cwl --archive hello.tar --extractfile hello.txt [workflow ] start [workflow ] starting step extract-specific-file [step extract-specific-file] start [job extract-specific-file] /tmp/guix-build-ccwl-website.drv-0/n9rv2__5$ tar \ --extract \ --file \ /tmp/guix-build-ccwl-website.drv-0/si1287k3/stg0c3a3765-0d7b-4afe-a712-5ceac3925357/hello.tar \ hello.txt [job extract-specific-file] completed success [step extract-specific-file] completed success [workflow ] completed success { "extracted-file": { "location": "file:///home/manimekalai/hello.txt", "basename": "hello.txt", "class": "File", "checksum": "sha1$a0b65939670bc2c010f4d5d6a0b3e4e4590fb92b", "size": 13, "path": "/home/manimekalai/hello.txt" } }Final process status is success
2.5 Passing input into the standard input stream of a command
Some commands read input from their standard input
stream. Let us do that from ccwl. The workflow below reports the size
of a file by passing it into the standard input of
wc. Notice the additional #:stdin keyword that
references the input file.
(define count-bytes (command #:inputs (file #:type File) #:run "wc" "-c" #:stdin file)) (workflow ((file #:type File)) (count-bytes #:file file))
Compiling and running this workflow gives us the following
output. Notice the file hello.txt passed into the standard
input of wc, and the file size reported in bytes.
$ ccwl compile pass-stdin.scm > pass-stdin.cwl $ cwltool pass-stdin.cwl --file hello.txt [workflow ] start [workflow ] starting step count-bytes [step count-bytes] start [job count-bytes] /tmp/guix-build-ccwl-website.drv-0/bcagjycr$ wc \ -c < /tmp/guix-build-ccwl-website.drv-0/dwur7cn6/stg213254cf-53bd-428d-966f-1f92d7fd91c1/hello.txt 13 [job count-bytes] completed success [step count-bytes] completed success [workflow ] completed success {}Final process status is success
2.6 Workflow with multiple steps
Till now, we have only written trivial workflows with a single command. If we were only interested in executing single commands, we would hardly need a workflow language! So, in this section, let us write our first multi-step workflow and learn how to connect steps together in an arbitrary topology.
2.6.1 pipe
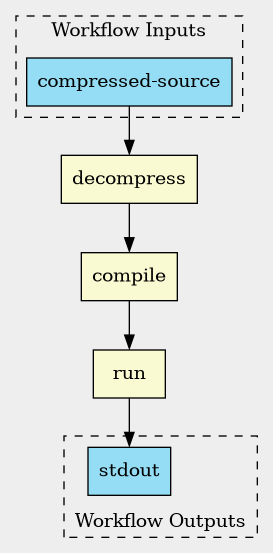
First, the simplest of topologies---a linear chain representing sequential execution of steps. The following workflow decompresses a compressed C source file, compiles and then executes it.
(define decompress (command #:inputs (compressed #:type File) #:run "gzip" "--stdout" "--decompress" compressed #:outputs (decompressed #:type stdout))) (define compile (command #:inputs (source #:type File) #:run "gcc" "-x" "c" source #:outputs (executable #:type File #:binding ((glob . "a.out"))))) (define run (command #:inputs executable #:run executable #:outputs (stdout #:type stdout) #:stdout "run-output.txt")) (workflow ((compressed-source #:type File)) (pipe (decompress #:compressed compressed-source) (compile #:source decompressed) (run #:executable executable)))
Notice the
pipe form in the
body of the workflow. The pipe form specifies a list of
steps to be executed sequentially. The inputs coming into
pipe are passed into the first step. Thereafter, the outputs
of each step are passed as inputs into the next. Note that this has
nothing to do with the Unix pipe. The inputs/outputs passed between
steps are general CWL inputs/outputs. They need not be the standard
stdin and stdout streams.
Writing this worklow to decompress-compile-run.scm, compiling and running it with the compressed C source file hello.c.gz gives us the following output.
$ ccwl compile decompress-compile-run.scm > decompress-compile-run.cwl $ cwltool decompress-compile-run.cwl --compressed-source hello.c.gz [workflow ] start [workflow ] starting step decompress [step decompress] start [job decompress] /tmp/guix-build-ccwl-website.drv-0/0e33jjzk$ gzip \ --stdout \ --decompress \ /tmp/guix-build-ccwl-website.drv-0/95ed6lme/stga563cd65-382f-40e6-ab16-04a523e739ba/hello.c.gz > /tmp/guix-build-ccwl-website.drv-0/0e33jjzk/21a353a8bcbb9b51752f74ed0945ea4c48a3f0d4 [job decompress] completed success [step decompress] completed success [workflow ] starting step compile [step compile] start [job compile] /tmp/guix-build-ccwl-website.drv-0/6ce4ecxn$ gcc \ -x \ c \ /tmp/guix-build-ccwl-website.drv-0/ktajnhcl/stg8d631768-798a-452b-b5e7-7007c2e08af0/21a353a8bcbb9b51752f74ed0945ea4c48a3f0d4 [job compile] completed success [step compile] completed success [workflow ] starting step run [step run] start [job run] /tmp/guix-build-ccwl-website.drv-0/l2umw00i$ /tmp/guix-build-ccwl-website.drv-0/oh1tb3bw/stgfabcdc7e-674b-4db8-b2f7-1c5857f48ffc/a.out > /tmp/guix-build-ccwl-website.drv-0/l2umw00i/run-output.txt [job run] completed success [step run] completed success [workflow ] completed success { "stdout": { "location": "file:///home/manimekalai/run-output.txt", "basename": "run-output.txt", "class": "File", "checksum": "sha1$a0b65939670bc2c010f4d5d6a0b3e4e4590fb92b", "size": 13, "path": "/home/manimekalai/run-output.txt" } }Final process status is success
The steps run in succession, and the stdout of the compiled executable is in run-output.txt. Success!
2.6.2 tee
Next, the tee topology. The following workflow computes three different checksums of a given input file.
(define md5sum (command #:inputs (file #:type File) #:run "md5sum" file #:outputs (md5 #:type stdout) #:stdout "md5")) (define sha1sum (command #:inputs (file #:type File) #:run "sha1sum" file #:outputs (sha1 #:type stdout) #:stdout "sha1")) (define sha256sum (command #:inputs (file #:type File) #:run "sha256sum" file #:outputs (sha256 #:type stdout) #:stdout "sha256")) (workflow ((file #:type File)) (tee (md5sum #:file file) (sha1sum #:file file) (sha256sum #:file file)))
Notice the
tee form in the
body of the workflow. The tee form specifies a list of steps
that are independent of each other. The inputs coming into
tee are passed into every step contained in the body of the
tee. The outputs of each step are collected together and
unioned as the output of the tee.

Writing this workflow to checksum.scm, compiling and running it with some file hello.txt gives us the following output.
$ ccwl compile checksum.scm > checksum.cwl $ cwltool checksum.cwl --file hello.txt [workflow ] start [workflow ] starting step md5sum [step md5sum] start [job md5sum] /tmp/guix-build-ccwl-website.drv-0/t5r2854_$ md5sum \ /tmp/guix-build-ccwl-website.drv-0/08dfqof1/stg0ab2218e-c70e-4a6a-b70a-d5e9246b14f4/hello.txt > /tmp/guix-build-ccwl-website.drv-0/t5r2854_/md5 [job md5sum] completed success [step md5sum] completed success [workflow ] starting step sha1sum [step sha1sum] start [job sha1sum] /tmp/guix-build-ccwl-website.drv-0/713_l5y1$ sha1sum \ /tmp/guix-build-ccwl-website.drv-0/z3orgla5/stg7d4c9e51-f4bb-4cc6-b7ae-2690cf3889c2/hello.txt > /tmp/guix-build-ccwl-website.drv-0/713_l5y1/sha1 [job sha1sum] completed success [step sha1sum] completed success [workflow ] starting step sha256sum [step sha256sum] start [job sha256sum] /tmp/guix-build-ccwl-website.drv-0/mtbwagjh$ sha256sum \ /tmp/guix-build-ccwl-website.drv-0/ux52wd23/stgec5a5ed4-38bd-4f37-8878-5056517af2f6/hello.txt > /tmp/guix-build-ccwl-website.drv-0/mtbwagjh/sha256 [job sha256sum] completed success [step sha256sum] completed success [workflow ] completed success { "md5": { "location": "file:///home/manimekalai/md5", "basename": "md5", "class": "File", "checksum": "sha1$79da688acf52eee10d03c3b77188303383b51cb8", "size": 128, "path": "/home/manimekalai/md5" }, "sha1": { "location": "file:///home/manimekalai/sha1", "basename": "sha1", "class": "File", "checksum": "sha1$607a21cda493e72046944b6e7c95e70bdb472f8d", "size": 136, "path": "/home/manimekalai/sha1" }, "sha256": { "location": "file:///home/manimekalai/sha256", "basename": "sha256", "class": "File", "checksum": "sha1$5fe10db016cca2b46c2a7b503129e396464d45ff", "size": 160, "path": "/home/manimekalai/sha256" } }Final process status is success
The MD5, SHA1 and SHA256 checksums are in the files md5, sha1 and sha256 respectively.
2.7 Let’s write a spell check workflow
Finally, let’s put together a complex workflow to understand how everything fits together. The workflow we will be attempting is a spell check workflow inspired by the founders of Unix 1 and by dgsh 2 . The workflow is pictured below. Let’s start by coding each of the steps required by the workflow.

The first command, split-words, splits up the
input text into words, one per line. It does this by invoking the
tr command to replace anything that is not an alphabetic
character with a newline. In addition, it uses the
--squeeze-repeats flag to prevent blank lines from appearing
in its output. Notice that no type is specified for the input
text. When no type is specified, ccwl assumes a
File type.
(define split-words (command #:inputs text #:run "tr" "--complement" "--squeeze-repeats" "A-Za-z" "\\n" #:stdin text #:outputs (words #:type stdout)))
We want our spell check to be case-insensitive. So, we
downcase all words. This is achieved using another invocation of the
tr command.
(define downcase (command #:inputs words #:run "tr" "A-Z" "a-z" #:stdin words #:outputs (downcased-words #:type stdout)))
For easy comparison against a dictionary, we want both our
words and our dictionary sorted and deduplicated. We achieve this by
invoking the sort command with the --unique
flag.
(define sort (command #:inputs words #:run "sort" "--unique" #:stdin words #:outputs (sorted #:type stdout)))
Finally, we compare the sorted word list with the sorted
dictionary to identify the misspellings. We do this using the
comm command.
(define find-misspellings (command #:inputs words dictionary #:run "comm" "-23" words dictionary #:outputs (misspellings #:type stdout) #:stdout "misspelt-words"))
Now, let’s wire up the workflow. First, we assemble the
split-words-downcase-sort-words arm of
the workflow. This arm is just a linear chain that can be assembled
using pipe. We will need to invoke the sort
command twice in our workflow. To distinguish the two invocations, CWL
requires us to specify a unique step id for each invocation. We do
this using the second element, (sort-words). To avoid name
conflicts, we also need to rename the output of the sort
command. The last step,
rename, a special ccwl
construct that, is used to achieve this. In this case, it renames the
sorted output of the sort command into sorted-words.
(workflow (text-file) (pipe (split-words #:text text-file) (downcase #:words words) (sort (sort-words) #:words downcased-words) (rename #:sorted-words sorted)))
Next, we assemble the split-dictionary arm of the
workflow. This arm is just a single step. Then, we connect up both the
arms using a tee. Here too, we have a step id and renaming
of intermediate inputs/outputs.
(workflow (text-file dictionary) (tee (pipe (split-words #:text text-file) (downcase #:words words) (sort (sort-words) #:words downcased-words) (rename #:sorted-words sorted)) (pipe (sort (sort-dictionary) #:words dictionary) (rename #:sorted-dictionary sorted))))
And finally, we use the outputs of both the arms of the
workflow together in the find-misspellings step.
(workflow (text-file dictionary) (pipe (tee (pipe (split-words #:text text-file) (downcase #:words words) (sort (sort-words) #:words downcased-words) (rename #:sorted-words sorted)) (pipe (sort (sort-dictionary) #:words dictionary) (rename #:sorted-dictionary sorted))) (find-misspellings #:words sorted-words #:dictionary sorted-dictionary)))
The complete workflow is as follows.
(define split-words (command #:inputs text #:run "tr" "--complement" "--squeeze-repeats" "A-Za-z" "\\n" #:stdin text #:outputs (words #:type stdout))) (define downcase (command #:inputs words #:run "tr" "A-Z" "a-z" #:stdin words #:outputs (downcased-words #:type stdout))) (define sort (command #:inputs words #:run "sort" "--unique" #:stdin words #:outputs (sorted #:type stdout))) (define find-misspellings (command #:inputs words dictionary #:run "comm" "-23" words dictionary #:outputs (misspellings #:type stdout) #:stdout "misspelt-words")) (workflow (text-file dictionary) (pipe (tee (pipe (split-words #:text text-file) (downcase #:words words) (sort (sort-words) #:words downcased-words) (rename #:sorted-words sorted)) (pipe (sort (sort-dictionary) #:words dictionary) (rename #:sorted-dictionary sorted))) (find-misspellings #:words sorted-words #:dictionary sorted-dictionary)))
When compiled and run with a text file and a dictionary, the misspelt words appear at the output.
$ ccwl compile spell-check.scm > spell-check.cwl $ cwltool spell-check.cwl --text-file spell-check-text.txt --dictionary dictionary [workflow ] start [workflow ] starting step sort-dictionary [step sort-dictionary] start [job sort-dictionary] /tmp/guix-build-ccwl-website.drv-0/ei0hb6pp$ sort \ --unique < /tmp/guix-build-ccwl-website.drv-0/ap48jaz2/stg88dae169-9a25-4b9d-b788-8d07c096bdb3/dictionary > /tmp/guix-build-ccwl-website.drv-0/ei0hb6pp/b46106ba82139f96387cdf28f4e26598ee542399 [job sort-dictionary] completed success [step sort-dictionary] completed success [workflow ] starting step split-words [step split-words] start [job split-words] /tmp/guix-build-ccwl-website.drv-0/kml0a65x$ tr \ --complement \ --squeeze-repeats \ A-Za-z \ \n < /tmp/guix-build-ccwl-website.drv-0/6m18iw35/stg14f07f58-4711-4ad2-b91a-1fb84556bb1d/spell-check-text.txt > /tmp/guix-build-ccwl-website.drv-0/kml0a65x/b1e06b887e107e825f495351b082229aa67b32e8 [job split-words] completed success [step split-words] completed success [workflow ] starting step downcase [step downcase] start [job downcase] /tmp/guix-build-ccwl-website.drv-0/9yy3ls9v$ tr \ A-Z \ a-z < /tmp/guix-build-ccwl-website.drv-0/ybxpfxvz/stgb701d300-0f7a-40f1-b0ba-6a1f9742a3b4/b1e06b887e107e825f495351b082229aa67b32e8 > /tmp/guix-build-ccwl-website.drv-0/9yy3ls9v/c3f95fa409fafb0d3fafdd2266dd88a22beb41e2 [job downcase] completed success [step downcase] completed success [workflow ] starting step sort-words [step sort-words] start [job sort-words] /tmp/guix-build-ccwl-website.drv-0/0xhfg2fj$ sort \ --unique < /tmp/guix-build-ccwl-website.drv-0/8r3npvh_/stg426a86ff-546d-4d3a-a08e-8e152194aebf/c3f95fa409fafb0d3fafdd2266dd88a22beb41e2 > /tmp/guix-build-ccwl-website.drv-0/0xhfg2fj/11840ff2b58051b75fe6966970b103a5c5cb6961 [job sort-words] completed success [step sort-words] completed success [workflow ] starting step find-misspellings [step find-misspellings] start [job find-misspellings] /tmp/guix-build-ccwl-website.drv-0/4wrsthll$ comm \ -23 \ /tmp/guix-build-ccwl-website.drv-0/0ow8aj_x/stgc852d846-0169-4f48-be58-9bd98bd4ecdb/11840ff2b58051b75fe6966970b103a5c5cb6961 \ /tmp/guix-build-ccwl-website.drv-0/0ow8aj_x/stg8ae20433-eef3-41f3-8620-6aee86eedbe5/b46106ba82139f96387cdf28f4e26598ee542399 > /tmp/guix-build-ccwl-website.drv-0/4wrsthll/misspelt-words [job find-misspellings] completed success [step find-misspellings] completed success [workflow ] completed success { "misspellings": { "location": "file:///home/manimekalai/misspelt-words", "basename": "misspelt-words", "class": "File", "checksum": "sha1$e701a33e7681ea185a709168c44e13217497d220", "size": 6, "path": "/home/manimekalai/misspelt-words" } }Final process status is success
3 Cookbook
3.1 Stage input files
When running command-line tools, CWL normally has separate
directories for input and output files. But, some command-line tools
expect their input and output files to be in the same directory, and
this may not sit well with them. In such situations, we can tell CWL
to stage the input file into the output directory. We may
express this in ccwl using the #:stage? parameter to the
inputs to be staged. Here is a rather concocted example.
(command #:inputs (file #:type File #:stage? #t) #:run "cat" "./$(inputs.file.basename)")
3.2 Pass in arbitrary CWL Requirements
Sometimes it is necessary to pass in arbitrary CWL
Requirments that are not explicitly supported by ccwl. You can do this
using the #:requirements parameter. The #:requirements parameter must be a scheme tree that is serializable
to YAML (to put it more bluntly, a tree that
guile-libyaml will
accept). Here are a couple of examples passing in an InlineJavascriptRequirement and a ResourceRequirement
respectively.
(command #:inputs (number #:type int) #:run "echo" "$(1 + inputs.number)" #:requirements ((InlineJavascriptRequirement)))
(command #:run "some-command" #:requirements ((ResourceRequirement (coresMin . 4))))
3.3 Prefix arguments
You want to be able to associate arguments of a command to a
prefix. For example, in the following example, we associate the input
output_filename to the prefix -o. Notice the
parentheses around -o output_filename.
(command #:inputs (source #:type File) (output_filename #:type string) #:run "gcc" source ("-o" output_filename))
3.4 Unseparated prefix arguments
Some programs don't like it when you separate arguments from
their prefixes. You can specify this using the #:separate?
flag.
(command #:inputs (source #:type File) (output_filename #:type string) #:run "gcc" source ("-o" output_filename #:separate? #f))This is executed as gcc foo.c -ofoo, rather than as gcc foo.c -o foo.
3.5 Array types
ccwl supports array types using the following syntax.
(workflow ((foo #:type (array string))) […])
Nested array types are also supported.
(workflow ((foo #:type (array (array string)))) […])
3.6 Array input item separators
Occasionally, it is required to serialize array type inputs
by separating them with a specific item separator. This can be
achieved by explicitly specifying a separator in the #:run
argument of command. For example, to use comma as the item
separator, you could do
(command #:inputs (messages #:type (array string)) #:run "echo" (array messages #:separator ","))If
[foo, bar, aal, vel] is passed in as messages, then the command invoked is echo
foo,bar,aal,vel.3.7 Scatter/gather
ccwl supports CWL’s dotproduct scatter/gather feature using
the following syntax. Here, the other-messages input to the
workflow is an array of strings that is scattered over the print step. Each run of the print step gets an element of
other-messages as its other-message argument.
(define print (command #:inputs (message #:type string) (other-message #:type string) #:run "echo" message other-message #:outputs (printed-output #:type stdout))) (workflow ((message #:type string) (other-messages #:type (array string))) (scatter (print #:message message) #:other-message other-messages))
3.8 Reuse workflows from other files
It's sometimes useful to break up long ccwl workflows into
separate files. You can load a ccwl workflow from another file using
ccwl-load. Here is an example that loads the checksum.scm from the
tee
section and reuses it in another workflow.
(define checksum (ccwl-load "checksum.scm")) (workflow ((input #:type File)) (pipe (checksum …) […]))
3.9 Reuse external CWL workflows
Even though you may be a ccwl convert (hurrah!), others may
not be. And, you might have to work with CWL workflows written by
others. ccwl permits easy reuse of external CWL workflows, and free
mixing with ccwl commands. Here is a workflow to find the string
length of a message, where one of the commands, echo, is
defined as an external CWL workflow. External CWL workflows are
referenced in ccwl using cwl-workflow. The identifiers and
types of the inputs/outputs are read from the YAML specification of
the external CWL workflow.
(define echo (cwl-workflow "echo.cwl")) (define string-length (command #:inputs file #:run "wc" "--chars" #:outputs (length #:type stdout) #:stdin file)) (workflow ((message #:type string)) (pipe (echo #:message message) (string-length #:file output)))echo.cwl is defined as
cwlVersion: v1.2 class: CommandLineTool baseCommand: echo arguments: ["-n"] inputs: message: type: string inputBinding: position: 1 outputs: output: type: stdout
3.10 The identity construct
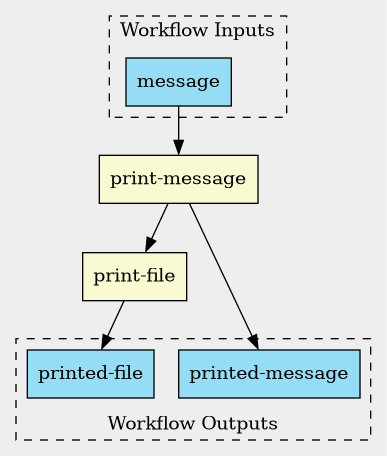
Sometimes, it is helpful for a step to simply copy all input
keys forward to the output. This is what the identity
construct is for. An example follows.
(define print-message (command #:inputs (message #:type string) #:run "echo" message #:outputs (printed-message #:type stdout))) (define print-file (command #:inputs (file #:type File) #:run "cat" file #:outputs (printed-file #:type stdout))) (workflow ((message #:type string)) (pipe (print-message #:message message) (tee (print-file #:file printed-message) (identity))))
3.11 Javascript expressions via ExpressionTool
ccwl supports CWL’s ExpressionTool using its
js-expression construct. The js-expression
construct may be invoked from within workflows just like command constructs can be. Here’s a workflow that uses js-expression to construct an array of numbers from 0 to
n-1.
(define iota (js-expression #:inputs (n #:type int) #:expression "$({\"sequence\": Array.from(Array(inputs.n).keys())})" #:outputs (sequence #:type (array int)))) (workflow ((n #:type int)) (iota #:n n))
4 Guide to the source code
This chapter is a guide to reading, understanding and hacking on the ccwl source code. You do not need to read this chapter to merely use ccwl to write your workflows. You only need to read this if you wish to understand and maybe improve the implementation of ccwl.
4.1 Important objects and functions
As described in the
Important Concepts section, ccwl is a statically typed
expression oriented language in which functions take one or more
arguments (either positional or named) and return one or more
outputs. There are different kinds of functions—namely commands,
javascript expressions, workflows and external CWL workflows. These
are represented by
<command>,
<js-expression>,
<workflow> and
<cwl-workflow> objects respectively. Inputs and outputs of
these functions are represented by
<input>
and
<output> objects respectively. Special macros—
command,
js-expression,
workflow
and
cwl-workflow
are provided to define <command>, <js-expression>,
<workflow> and <cwl-workflow> objects
respectively. These macros provide syntax validation and present a
more concise interface to users. <input> and <output> objects are never defined on their own by the user, but
rather are inferred by the aforementioned macros.
ccwl introduces the notion of a
<key> that is a
generalization of <input> and <output>
objects. Keys flow through workflow steps and string them
together. Keys in the ccwl DSL are analogous to variable names in a
regular programming language. The
collect-steps function
traverses workflow expression trees and produces a list of CWL
steps. ccwl constructs such as pipe, tee, identity, rename, scatter, etc. are implemented
in the collect-steps function.
4.2 Source tree organization
Here’s a short summary of what some important files in the source tree contain.
- ccwl/ccwl.scm
- Core functionality—the functions, keys, input/output objects, etc.— of the ccwl DSL
- ccwl/cwl.scm
- and
- ccwl/graphviz.scm
- Serialization concerns to CWL and dot respectively
- ccwl/yaml.scm
- Library to serialize scheme trees to YAML in the manner of guile-json to JSON
- ccwl/ui.scm
- Command-line reporting of errors in the context of the user’s workflow description
4.3 Contributing
ccwl is developed on GitHub at https://github.com/arunisaac/ccwl. Feedback, suggestions, feature requests, bug reports and pull requests are all welcome. Unclear and unspecific error messages are considered a bug. Do report them!